브라우저가 화면을 표시하는 과정3 : Parsing the HTML
1. Navigation
2. Fetching Data
3. parsing the HTML
4. parsing the CSS
5. executing the Javascript
6. creating the accessibility tree
7. the Render Tree
단계 중 세 번째입니다.
두 번째 단계 Fetching Data에서 서버로부터 html을 받았습니다. 이제 서버로부터 받은 html 파일을 parsing(파싱)할 차례입니다.
파싱이란 무엇일까요? 파싱이란 한국말로 하면 '구문분석'인데요, 파싱을 이해하는데 큰 도움은 되지 않지만 알고 보면 적절한 단어인 것 같습니다. 단지 텍스트로 이루어진 파일(html)을 브라우저가 이해할 수 있고 작업할 수 있는 코드로 변환하는 것입니다.
JSON.parse()를 사용하면 단지 문자열에 불과한 "{}"도 자바스크립트가 이해할 수 있고 프로토타입을 갖춘 Object가 되듯이 html을 파싱 하면 단지 텍스트일 뿐인 html이 브라우저가 작업할 수 있는 코드로 변환된다 생각하면 될 것 같습니다. 이 과정은 브라우저 엔진(자바스크립트 엔진과 다름)에서 처리됩니다.
브라우저엔진은 모든 브라우저의 핵심 구성요소이고 html과 css를 결합하여 화면에 웹페이지를 그리는 역할을 합니다. 또한 어떤 코드가 상호작용하는지 찾아내는 역할도 합니다. 브라우저 엔진에도 종류가 있는데 아래 세가지의 점유율이 큽니다
Gecko
파이어폭스용으로 Mozila에서 개발했고, 과거에는 많은 브라우저가 사용했지만 지금은 파이어폭스, 토어, 워터폭스에서 사용합니다
Webkit
애플이 사파리용으로 개발했습니다.
Blink, part of Chromium
Webkit의 포크로 시작했고 크롬용으로 구글에서 개발했습니다. 마찬가지로 여러 브라우저에서 사용합니다.
이런애들이 바로 html을 파싱 하는 브라우저엔진입니다.
html파일이 첫 14kb보다 크더라도 브라우저는 가지고 있는 데이터를 기반으로 파싱을 시작하고 랜더링을 시도합니다.
(파일이 여러패킷으로 나눠져도 기다리지 않고 바로바로 파싱하고 랜더링 한다는 뜻인 듯..)
html파싱은 tokenization과 tree construction이라는 두 단계를 포함합니다. tree construction은 dom tree를 만드는 만드는 과정입니다.
Tokenization
토크나이징은 어휘 분석입니다. 단지 텍스트인 html을 가져다가 브라우저엔진이 보기에 유의미한 단위로 끊어서 토큰을 만들어내는 과정입니다. 토크나이징의 결과는 DOCTYPE, 시작태크(<tag>), 종료태그(</ tag>), 자체종료태그(<tag />), 어트리뷰트 name, value, characters, text와 같은 토큰입니다.
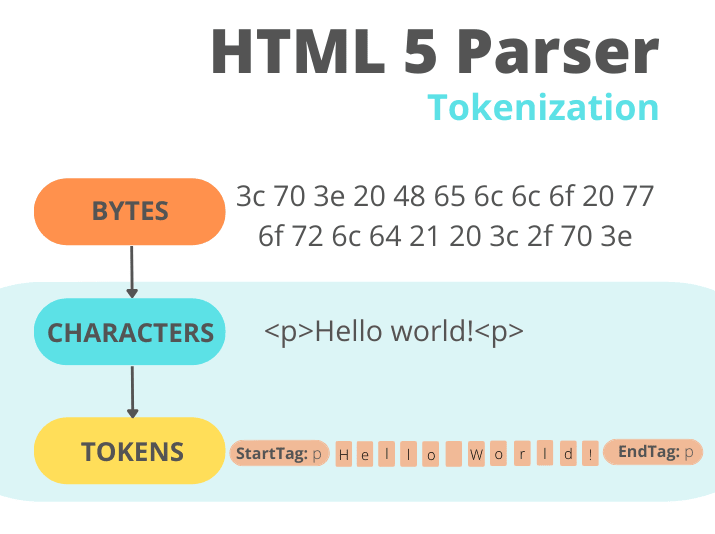
그림을 보면 이해가 더 쉬운데요, 서버로부터 받은 상태는 bytes입니다. 우리가 작성해서 서버에 올려놓은 html파일 그대로 <body><div></div></body>이런 코드가 왔다 갔다 하는 게 아니라 서버가 보낼 수 있는 형태인 bytes로 바뀌어서 브라우저와 통신하고, 브라우저는 이것을 받아서 토크나이징과정을 거쳐 유의미한 태그들을 얻는 것으로 이해했습니다. 이제 유의미한 태그들을 얻었으니 본격적으로 dom을 만들어볼 수 있습니다.
Building the DOM
첫 번째 토근이 생성된 뒤에 트리가 만들어지기 시작합니다. 토크나이징 과정에서 생성된 토큰을 기반으로 트리구조의 자료구조(dom)를 만듭니다. dom트리는 html문서의 구조를 설명합니다.
( 여기서 추가 설명하자면.. 파싱을 했다고 하더라도 html태그 안에 head랑 body가 있고 head에 link태그가 있고 body 안에 script가 있고.. 이런 구조를 브라우저가 알지는 못합니다. 눈이 있는 게 아니니까요. 그래서 우리가 작성한 html의 구조를 브라우저엔진이 알아듣기 위해 트리구조를 가진 자료구조 dom을 만드는 것 같습니다.)
<html> 태그는 첫 번째 태그이고 트리구조의 최상위 루트 노드입니다. 트리는 각각의 태그들 간의 계층적 관계를 반영합니다. 우리는 부모노드도 가지고 있고, 어떤 태그 아래 감싸진 자식노드도 있습니다. 당연히 노드가 많을수록 돔트리를 만드는데 시간도 오래 걸립니다.
( 위에서 설명한 html의 부모자식형제관계를 만드는 과정을 이렇게 설명했네요.)
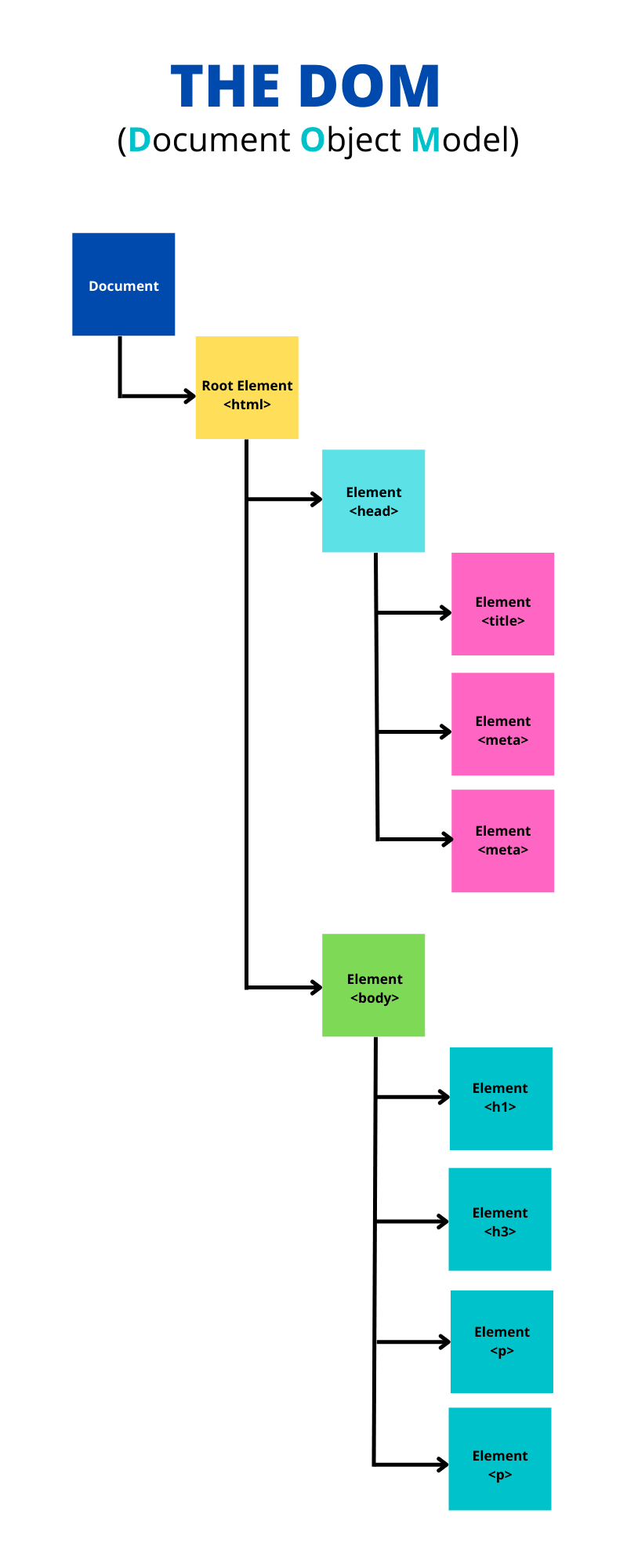
트리구조를 이해하기 쉽게 위 이미지를 참고하면 되겠습니다.
다음은 해석이 어려운데,, 이 모든 과정은 모두 끝나고 한 번에 시작하고 하는 게 아니라 계속해서 연달아 처리되는 과정이라는 말 같습니다.
(링크에서 직접 보시고 가르침을 주시면 감사하겠습니다..ㅜㅜ)
parser는 위에서 아래로 한 줄씩 작동합니다. 한줄씩 처리하다가 non-blocking리소스, 예를 들면 이미지를 만나면 브라우저는 서버에 이미지를 요청하고 계속 파싱을 해나갑니다. 반면에 blocking리소스 예를들면 head태그에 있는 css나 js파일, 혹은 cdn에 있는 폰트 등을 만날 때는 조금 다릅니다. 이런 blocking리소스가 전부 다운로드될 때까지 파싱을 멈춥니다! 이것이 <script> 태그를 html파일의 가장 마지막에 넣는 이유입니다. 혹은 head태그에 꼭 넣고 싶다면 defer 나 async 어트리뷰트를 사용해야 하는 이유입니다.
async, defer 어트리뷰트를 사용하면 해당 리소스의 다운로드가 html파싱을 막지 않고 비동기적으로 진행되도록 합니다. 단, async는 리소스 다운로드가 끝난 직후, html파싱이 아직 진행되고 있더라도 다운로드 즉시 실행합니다. 반면 defer는 비동기적으로 다운로드 함은 물론이고 html파싱이 모두 끝나고 나서야 실행되도록 합니다. 개발자의 의도대로라면 defer를 사용하게 되지 않을까 합니다.
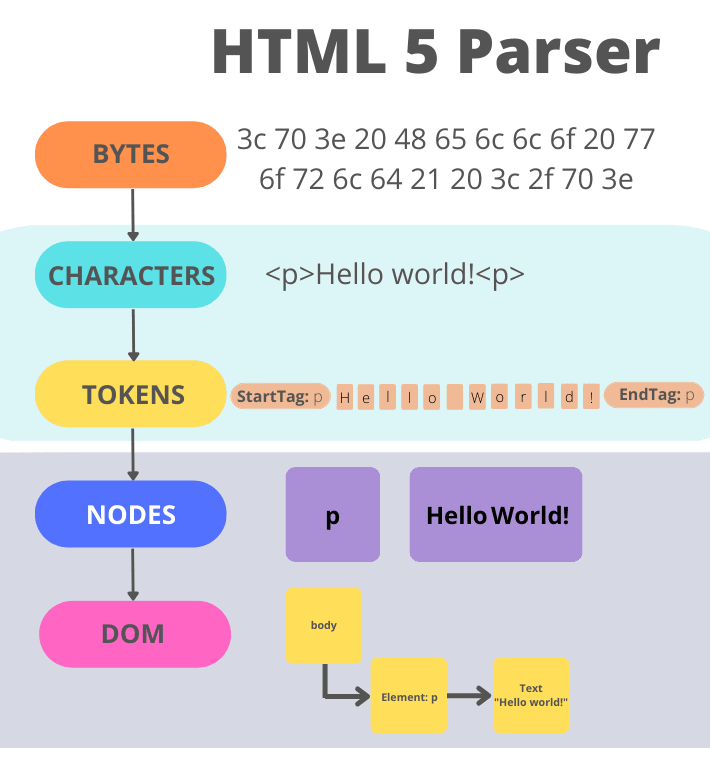
지금까지 설명한 전체 과정은 위 이미지와 같습니다.
이러한 blocking리소스를 다루는 방법으로 브라우저 제조사들은 2008년에 pre-loader를 개발했습니다. blocking 때문에 html파싱이 늦어져서 전체적으로 웹사이트 랜더링이 느려지니 이것을 개선하기 위해서겠죠? pre-loader를 사용하면 두 번째 파서가 html에서 블록킹이 유발될 자원(css, js, 폰트 등)을 미리 찾아내서 다운로드합니다. 목표는 첫 번째 파서가 <script> 같은 태그에 도달했을 때 이미 다운로드가 완료되었기를 목표로 합니다.
(번역을 하다 보니 오히려 이해가 어려운데, 쉽게 생각해 보자면 파싱을 시작할 때 원래의(첫번째) 파서가 <script> 태그에 도달해서야 blocking을 할지 async를 할지 defer를 할지 결정하는게 아니라 처음 시작할때 두 번째 파서가 블록킹이 발생할만한 리소스를 찾아서 어차피 다운로드할 리소스이니, 파싱과 동시에 다운로드하겠다는 뜻으로 해석됩니다. 의도는 메인 파서가 <script> 태그에 도달했을 때는 이미 다운로드가 다 되었으면 좋겠다는 뜻이겠죠!?)
여기까지가 html파싱이었습니다.
최근에 크롬에서
A Parser-blocking, cross-origin script,
https://paul.kinlan.me/ad-inject.js, is invoked via document.write().
This may be blocked by the browser if the device has poor network connectivity.이런 경고를 본 경험이 있습니다. 파싱이 블로킹되어서 2g 같은 네트워크가 안 좋은 환경에서 blocked 될 수 있다는 경고입니다.
https://developer.chrome.com/blog/removing-document-write/
가끔 카카오 지도 같은 외부 스크립트를 <script> 태그로 가져와서 사용하는 경우가 있는데요, 위에서 알아본 바와 같이 html파싱에 문제가 있을 수 있으니 비동기처리를 하거나 html아래쪽으로 옮기거나 해야 할 필요가 있다고 알려주는 경고입니다.
async와 defer의 차이는
https://yceffort.kr/2020/10/defer-than-async
왜 Async 보다는 Defer를 써야할까
웹사이트의 렌더링 성능을 최적화하면서, 가장 중점적으로 살펴봐야 할 것은 렌더링을 막는 자바스크립트 실행이다. 그런데 종종, 블로킹 자바스크립트의 원인이 async 태그라는 것을 발견하게
yceffort.kr
위 블로그에서 자세히 설명해주고 계십니다.
https://dev.to/arikaturika/how-web-browsers-work-parsing-the-html-part-3-with-illustrations-45fi
How web browsers work - parsing the HTML (part 3, with illustrations)📜🔥
Until now we discussed navigation and data fetching. Today we're going to talk about parsing in...
dev.to
https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work
Populating the page: how browsers work - Web performance | MDN
Users want web experiences with content that is fast to load and smooth to interact with. Therefore, a developer should strive to achieve these two goals.
developer.mozilla.org